
INTRO
The purpose of creating WordSkew is to investigate the ways in which language is sensitive to the structure of texts and to discourse in general. There are, of course, many facets to such a wide-ranging statement of interest. One constraining aspect of the current approach lies in looking at frequency and applying corpus techniques, while at the same time taking account of position and distribution in a text, with the aim of moving towards a usage-based discourse grammar. We have ways of talking about discourse at different levels. One is the order inherent in constructions and so if we have no matter then it is either likely to occur as an adverbial or as part of a larger construction with a WH-element and a clause or two. How are these uses distributed in texts? Is no matter more likely to occur at the beginning or end of sentences (or utterances)? What is the distribution of the longer no matter construction in newspaper articles?
WordSkew video manual
Basics
The software shown in the videos may differ slightly from the version you have, especially if you are using the Mac version.
Since the purpose of WordSkew is to look at usage with respect to text or discourse segments, it is crucial to indicate the format of the texts before loading the corpus files. Here is a brief intro to text settings and loading corpus files
Along the sames lines, a search is not by default processing the corpus as if it were an undifferentiated whole and so in General Options you specify how you wish to process the different text segments.
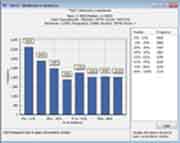
The word/phrase search is straightforward. Here we perform a search for the. Using this Word/phrase search gives results similar to those in the graphic above. If you want to search for of the, simply type the phrase in the search textbox.
In many cases, it will be necessary to normalise the results. We see in the results that the frequency counts for "P" in the middle of the sentence are very high. To make those frequencies comparable with those of the other positions in the sentence, we need to normalise the raw frequencies
Simple wildcard searches can make a single search more flexible, allowing you to capture a word lemma (as long as it is regular) rather than a word. The results obtained still have to be checked, however. Here is short intro to wildcards. An alternative type of wildcard character is @, which allows the capture of a variable range of words within a search string.
Another consequence of not searching the corpus as a whole is that there are some complexities associated with counts such as the number of matches of the search term. It is very important to see how the settings in General Options affects the results. Video coming.
Specialised searches
Regular expression search
(POS) Tag search
Batch search